R을 이용한 통계 분석 - 히스토그램, 밀도그림
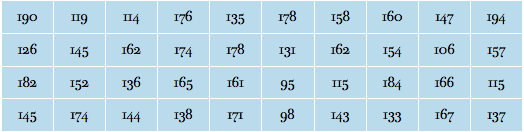
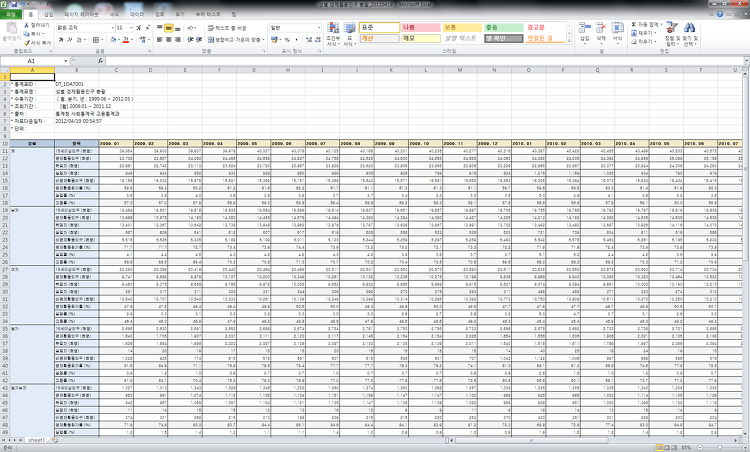
히스토그램 - 연속형 자료에서 도수분포표를 기초로 하여 각 계급에 대해 범주형 자료에서 막대그래프와 같은 모양의 그림을 히스토그램이라 합니다. 히스토그램은 양적 자료의 분포를 살펴 볼 때 사용 되는 것으로 많은 양의 자료를 살펴 볼 때 적합합니다. 다음은 A대학의 통계학과 졸업 대상자 40명의 졸업 전공 시험이다. 위의 데이터로 히스토그램을 그려보자.# 데이터 입력finaltestscore = c(190,119,114,176,135,178,158,160,147,194,126,145,162,174,178,131,162,154,106,157,182,152,136,165,161,95,115,184,166,115,145,174,144,138,171,98,143,133,167,137) # 히스토그램을 그리게 됩니..